finalvoidpushTask(ForkJoinTask<?>t){ForkJoinTask<?>[]q;ints,m;if((q=queue)!=null){// ignore if queue removedlongu=(((s=queueTop)&(m=q.length-1))<<ASHIFT)+ABASE;UNSAFE.putOrderedObject(q,u,t);queueTop=s+1;// or use putOrderedIntif((s-=queueBase)<=2)pool.signalWork();elseif(s==m)growQueue();}}
无锁的数据结构的基础:Compare and Swap现在所有的CPU指令都支持CAS的原子操作,X86对应的指令是CMPXCHG汇编指令。CAS是一组原子指令来达到同步的目的,它去拿一个值跟内存中一个值进行比较,只有相等的情况,才会给这个内存的值赋予新的值。整个操作都在一个原子操作内完成的。CAS操作比锁消耗资源少的多,因为它们不牵涉操作系统,它们直接在CPU上操作。
循环时间长开销大。自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
首先,Disruptor根本就不用锁。取而代之的是,在需要确保操作是线程安全的(特别是,在多生产者的环境下,更新下一个可用的序列号)地方,我们使用CAS(Compare And Swap/Set)操作
去掉伪共享
1) CPU及缓存介绍
CPU是你机器的心脏,最终由它来执行所有运算和程序。主内存(RAM)是你的数据(包括代码行)存放的地方。CPU和主内存之间有好几层缓存,因为即使直接访问主内存也是非常慢的。如果你正在多次对一块数据做相同的运算,那么在执行运算的时候把它加载到离CPU很近的地方就有意义了(比如一个循环计数-你不想每次循环都跑到主内存去取这个数据来增长它吧)。
越靠近CPU的缓存越快也越小。所以L1缓存很小但很快(译注:L1表示一级缓存),并且紧靠着在使用它的CPU内核。L2大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用。L3在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有 CPU 核共享。最后,你拥有一块主存,由全部插槽上的所有 CPU 核共享。
当CPU执行运算的时候,它先去L1查找所需的数据,再去L2,然后是L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。
try{thrownewFileNotFoundException();}catch(FileNotFoundExceptionfile){System.out.println("File Not Found Exception");}catch(IOExceptionio){System.out.println("IO Exception");}
InputStreaminput=null;try{input=newFileInputStream("myFile.txt");//do something with the stream}catch(IOExceptione){thrownewWrapperException(e);}finally{try{input.close();}catch(IOExceptione){thrownewWrapperException(e);}}
正确的写法:
123456789101112
try{input=newFileInputStream("myFile.txt");//do something with the stream}catch(IOExceptione){//first catch blockthrownewWrapperException(e);}finally{try{if(input!=null)input.close();}catch(IOExceptione){//second catch blockthrownewWrapperException(e);}}
try( FileInputStream input = new FileInputStream("file.txt");
BufferedInputStream bufferedInput = new BufferedInputStream(input)
) {
input, bufferedInput都会自动关闭,但是他们关闭的顺序正好和他们申明顺序相反。
6.2 特性二 Java7 之前我们catch住多个Exception
123456789
try{// execute code that may throw 1 of the 3 exceptions below.}catch(SQLException){logger.log(e);}catch(IOExceptione){logger.severe(e);}catch(Exceptione){logger.severe(e);}
Java 7之后 我们可以用
1234567
try{// execute code that may throw 1 of the 3 exceptions below.}catch(SQLException|IOExceptione){logger.log(e);}catch(Exceptione){logger.severe(e);}
HashIterator(){expectedModCount=modCount;if(size>0){// advance to first entryEntry[]t=table;while(index<t.length&&(next=t[index++])==null);}}finalEntry<K,V>nextEntry(){if(modCount!=expectedModCount)thrownewConcurrentModificationException();Entry<K,V>e=next;if(e==null)thrownewNoSuchElementException();if((next=e.next)==null){Entry[]t=table;while(index<t.length&&(next=t[index++])==null);}current=e;returne;}publicvoidremove(){if(current==null)thrownewIllegalStateException();if(modCount!=expectedModCount)thrownewConcurrentModificationException();Objectk=current.key;current=null;HashMap.this.removeEntryForKey(k);expectedModCount=modCount;}
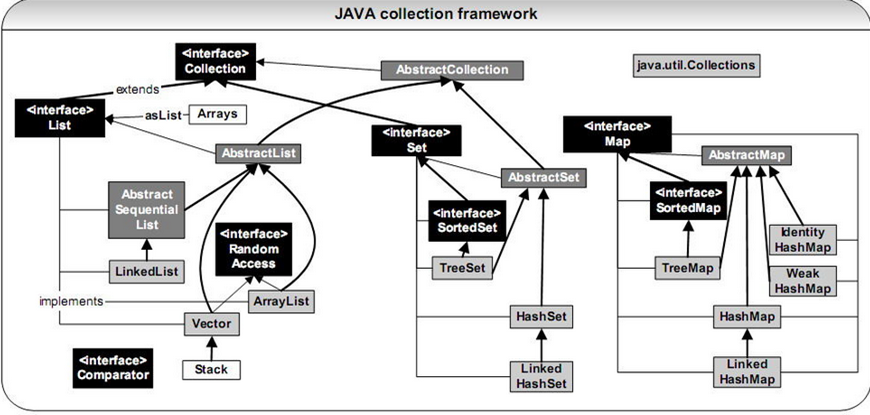
publicclassHashSet<E>extendsAbstractSet<E>implementsSet<E>,Cloneable,java.io.Serializable{staticfinallongserialVersionUID=-5024744406713321676L;//使用HashMap的key保存HashSet中的所有元素privatetransientHashMap<E,Object>map;// Dummy value to associate with an Object in the backing Map//定义一个虚拟的Object对象作为HashMap的valueprivatestaticfinalObjectPRESENT=newObject();/** * Constructs a new, empty set; the backing <tt>HashMap</tt> instance has * default initial capacity (16) and load factor (0.75). *///初始化HashSet,底层会初始化一个HashMappublicHashSet(){map=newHashMap<E,Object>();}//指定初始容量和loadfactor来初始化HashSet,其实就是初始化HashMap//loadfactor = 散列表的实际元素数目(n)/ 散列表的容量(m)publicHashSet(intinitialCapacity,floatloadFactor){map=newHashMap<E,Object>(initialCapacity,loadFactor);}/** * Constructs a new, empty set; the backing <tt>HashMap</tt> instance has * the specified initial capacity and default load factor (0.75). * * @param initialCapacity the initial capacity of the hash table * @throws IllegalArgumentException if the initial capacity is less * than zero */publicHashSet(intinitialCapacity){map=newHashMap<E,Object>(initialCapacity);}/** * Constructs a new, empty linked hash set. (This package private * constructor is only used by LinkedHashSet.) The backing * HashMap instance is a LinkedHashMap with the specified initial * capacity and the specified load factor. * * @param initialCapacity the initial capacity of the hash map * @param loadFactor the load factor of the hash map * @param dummy ignored (distinguishes this * constructor from other int, float constructor.) * @throws IllegalArgumentException if the initial capacity is less * than zero, or if the load factor is nonpositive */HashSet(intinitialCapacity,floatloadFactor,booleandummy){map=newLinkedHashMap<E,Object>(initialCapacity,loadFactor);}/** * Returns an iterator over the elements in this set. The elements * are returned in no particular order. * * @return an Iterator over the elements in this set * @see ConcurrentModificationException *///调用Map的keyset来返回迭代器publicIterator<E>iterator(){returnmap.keySet().iterator();}/** * Adds the specified element to this set if it is not already present. * More formally, adds the specified element <tt>e</tt> to this set if * this set contains no element <tt>e2</tt> such that * <tt>(e==null ? e2==null : e.equals(e2))</tt>. * If this set already contains the element, the call leaves the set * unchanged and returns <tt>false</tt>. * * @param e element to be added to this set * @return <tt>true</tt> if this set did not already contain the specified * element *///将e作为key插入了Hashmappublicbooleanadd(Ee){returnmap.put(e,PRESENT)==null;}/** * Returns a shallow copy of this <tt>HashSet</tt> instance: the elements * themselves are not cloned. * * @return a shallow copy of this set *///拷贝通过两步完成:1、通过调用super.clone完成父类的拷贝;2、通过调用map.clone()完成对成员变量map的拷贝。注意map的拷贝也是调用super.clone完成,所以拷贝都是浅拷贝。另外需要注意拷贝过程会抛出CloneNotSupportedException异常,这是一个检查异常。publicObjectclone(){try{HashSet<E>newSet=(HashSet<E>)super.clone();newSet.map=(HashMap<E,Object>)map.clone();returnnewSet;}catch(CloneNotSupportedExceptione){thrownewInternalError();}}
(1) LRU缓存
我们用缓存来存放以前读取的数据,而不是直接丢掉,这样,再次读取的时候,可以直接在缓存里面取,而不用再重新查找一遍,这样系统的反应能力会有很大提高。但是,当我们读取的个数特别大的时候,我们不可能把所有已经读取的数据都放在缓存里,毕竟内存大小是一定的,我们一般把最近常读取的放在缓存里。
LRU缓存利用了这样的一种思想。LRU是Least Recently Used 的缩写,翻译过来就是“最近最少使用”,也就是说,LRU缓存把最近最少使用的数据移除,让给最新读取的数据。而往往最常读取的,也是读取次数最多的,所以,利用LRU缓存,我们能够提高系统的性能。
(2) 为什么是LinkedHashMap
第一,它的数据结构包含一个双向链表,其源代码片段如下:
123456789101112
publicclassLinkedHashMap<K,V>extendsHashMap<K,V>implementsMap<K,V>{/** * The head of the doubly linked list. */privatetransientEntry<K,V>header;其中Entry的定义的代码片段如下:/** * LinkedHashMap entry. */privatestaticclassEntry<K,V>extendsHashMap.Entry<K,V>{// These fields comprise the doubly linked list used for iteration. Entry<K,V>before,after;
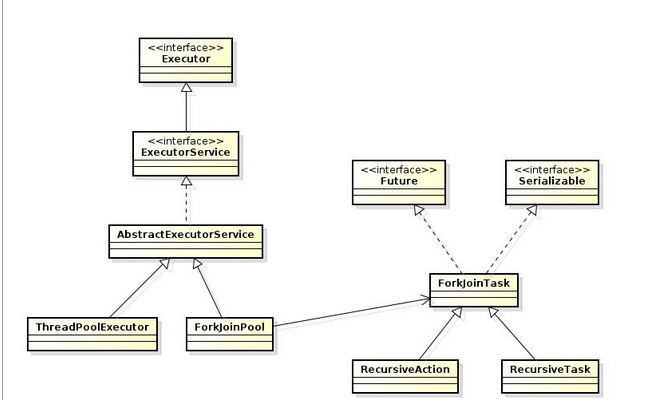


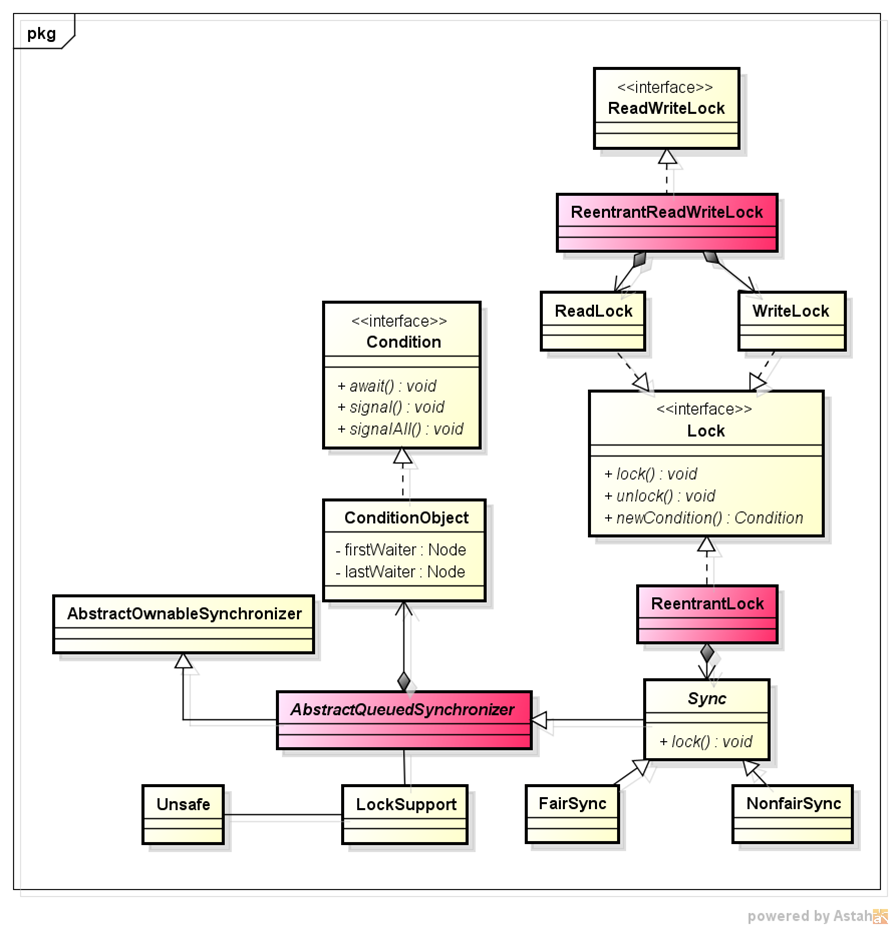
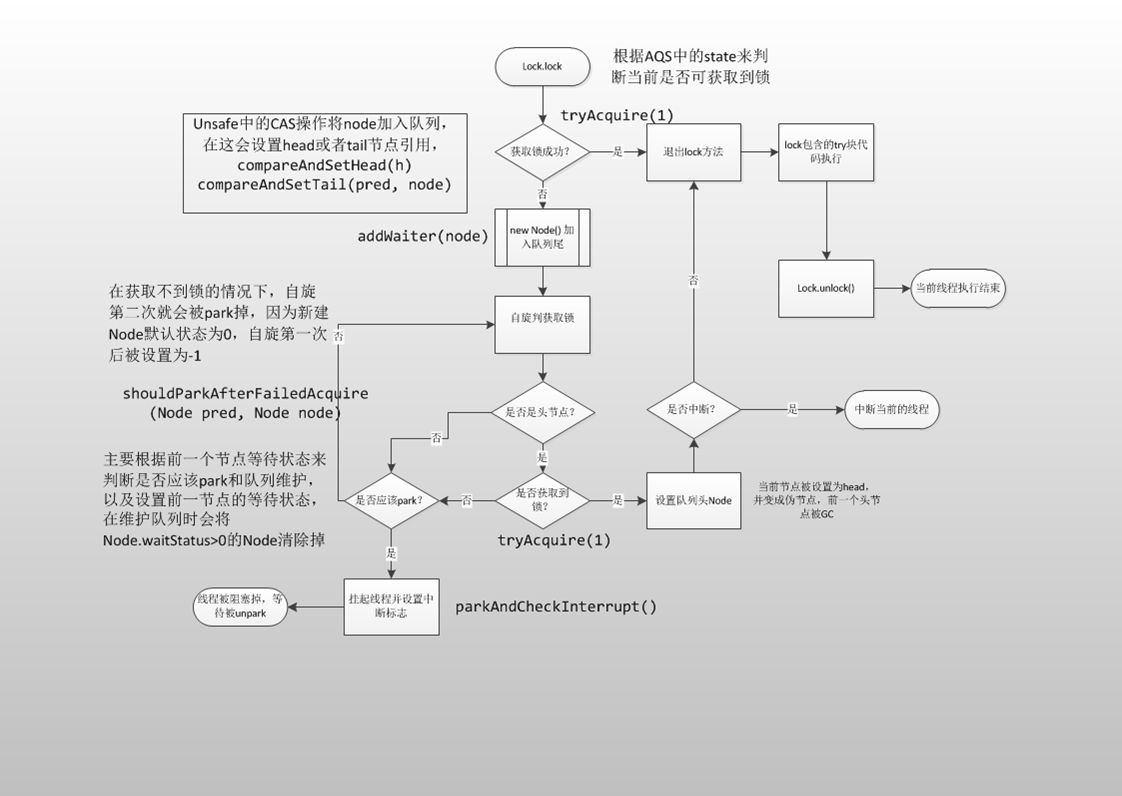
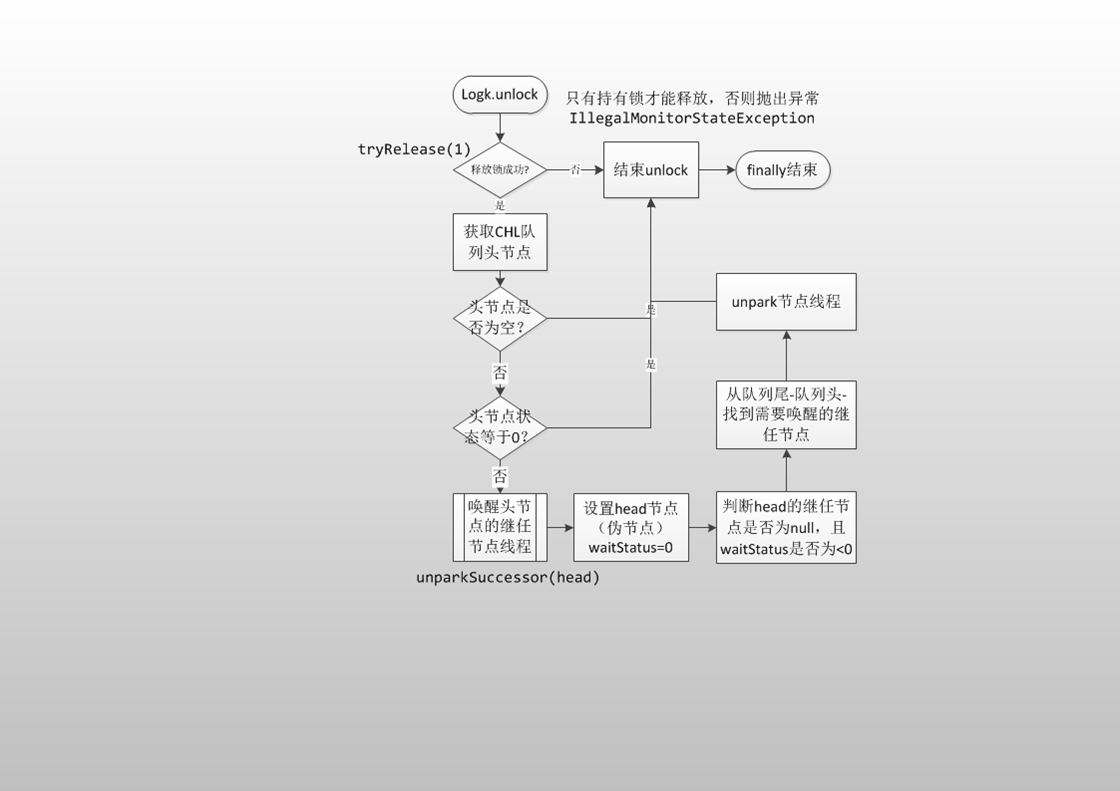

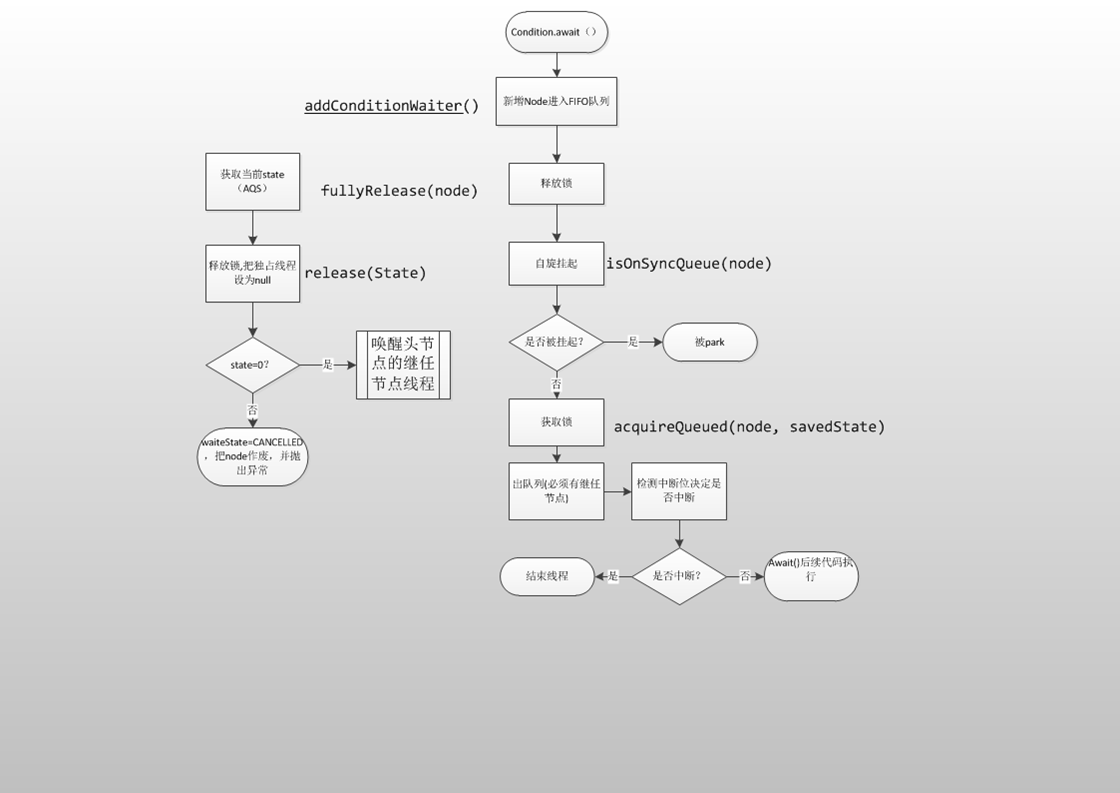

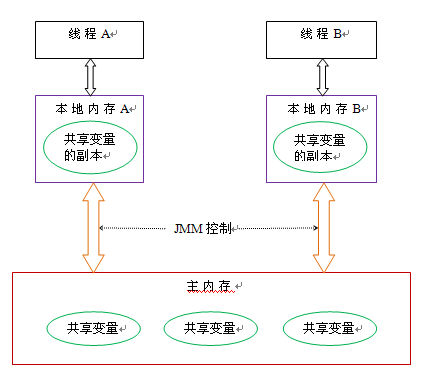 如何保证多个线程操作主内存的数据完整性是一个难题,Java内存模型也规定了工作内存与主内存之间交互的协议,首先是定义了8种原子操作:
如何保证多个线程操作主内存的数据完整性是一个难题,Java内存模型也规定了工作内存与主内存之间交互的协议,首先是定义了8种原子操作: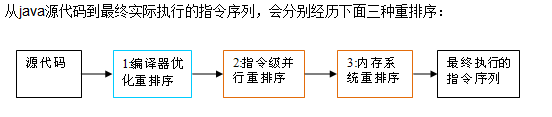
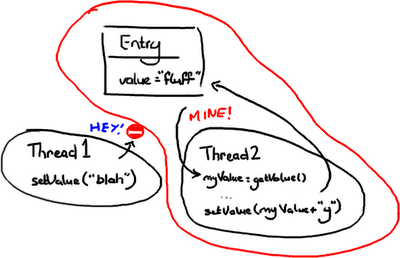 只要线程2一获得Entry 的互斥锁,它就会阻击其它线程去改变它,然后它就可以随意做它要做的事情,设置值,然后做其它事情。
只要线程2一获得Entry 的互斥锁,它就会阻击其它线程去改变它,然后它就可以随意做它要做的事情,设置值,然后做其它事情。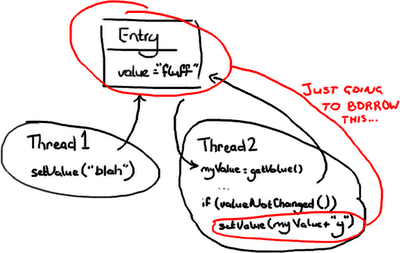 在这种情况,当线程2需要去写Entry时才会去锁定它.它需要检查Entry自从上次读过后是否已经被改过了。如果线程1在线程2读完后到达并把值改为”blah”,线程2读到了这个新值,线程2不会把"fluffy"写到Entry里并把线程1所写的数据覆盖.线程2会重试(重新读新的值,与旧值比较,如果相等则在变量的值后面附上’y’)
在这种情况,当线程2需要去写Entry时才会去锁定它.它需要检查Entry自从上次读过后是否已经被改过了。如果线程1在线程2读完后到达并把值改为”blah”,线程2读到了这个新值,线程2不会把"fluffy"写到Entry里并把线程1所写的数据覆盖.线程2会重试(重新读新的值,与旧值比较,如果相等则在变量的值后面附上’y’)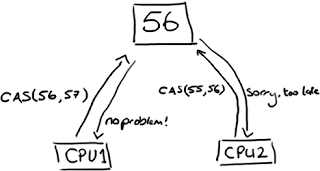


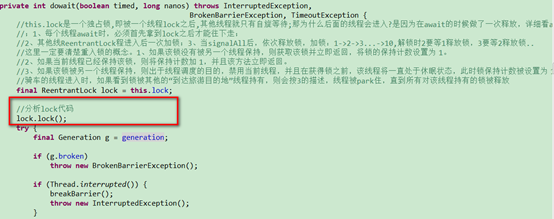
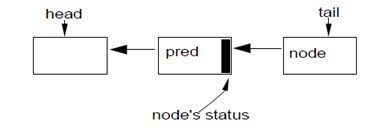
 lock是一个reetrantlock,是独占锁。独占锁的特征是,lock被thread0锁定之后,其他线程,包括同为“beginning”的线程,都无法获取到锁。Reetrantlock实际上是委托类中的非公平锁。非公平锁首先通过CAS设置AQS独占线程而持有锁:
% img center /images/juc-images/java-cyclicBarrier-4.png %}
lock是一个reetrantlock,是独占锁。独占锁的特征是,lock被thread0锁定之后,其他线程,包括同为“beginning”的线程,都无法获取到锁。Reetrantlock实际上是委托类中的非公平锁。非公平锁首先通过CAS设置AQS独占线程而持有锁:
% img center /images/juc-images/java-cyclicBarrier-4.png %}


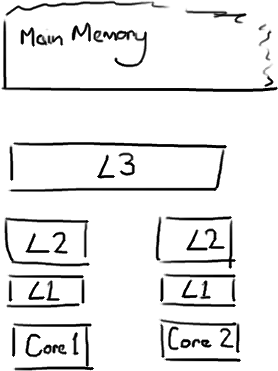 越靠近CPU的缓存越快也越小。所以L1缓存很小但很快(译注:L1表示一级缓存),并且紧靠着在使用它的CPU内核。L2大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用。L3在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有 CPU 核共享。最后,你拥有一块主存,由全部插槽上的所有 CPU 核共享。
当CPU执行运算的时候,它先去L1查找所需的数据,再去L2,然后是L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。
越靠近CPU的缓存越快也越小。所以L1缓存很小但很快(译注:L1表示一级缓存),并且紧靠着在使用它的CPU内核。L2大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用。L3在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有 CPU 核共享。最后,你拥有一块主存,由全部插槽上的所有 CPU 核共享。
当CPU执行运算的时候,它先去L1查找所需的数据,再去L2,然后是L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。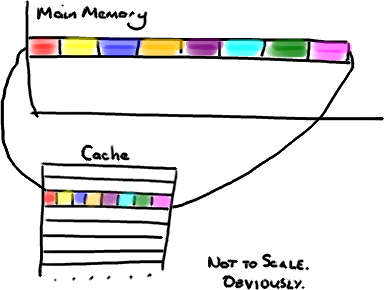 (为了简化,我将忽略多级缓存)
(为了简化,我将忽略多级缓存)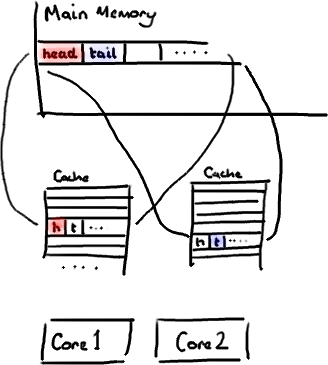 听想来不错。直到你意识到tail正在被你的生产者写入,而head正在被你的消费者写入。这两个变量实际上并不是密切相关的,而事实上却要被两个不同内核中运行的线程所使用。
听想来不错。直到你意识到tail正在被你的生产者写入,而head正在被你的消费者写入。这两个变量实际上并不是密切相关的,而事实上却要被两个不同内核中运行的线程所使用。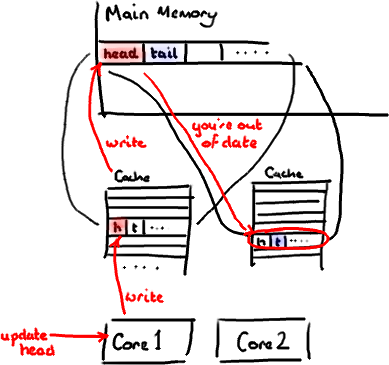 设想你的消费者更新了head的值。缓存中的值和内存中的值都被更新了,而其他所有存储head的缓存行都会都会失效,因为其它缓存中head不是最新值了。请记住我们必须以整个缓存行作为单位来处理(译注:这是CPU的实现所规定的,详细可参见深入分析Volatile的实现原理),不能只把head标记为无效。
设想你的消费者更新了head的值。缓存中的值和内存中的值都被更新了,而其他所有存储head的缓存行都会都会失效,因为其它缓存中head不是最新值了。请记住我们必须以整个缓存行作为单位来处理(译注:这是CPU的实现所规定的,详细可参见深入分析Volatile的实现原理),不能只把head标记为无效。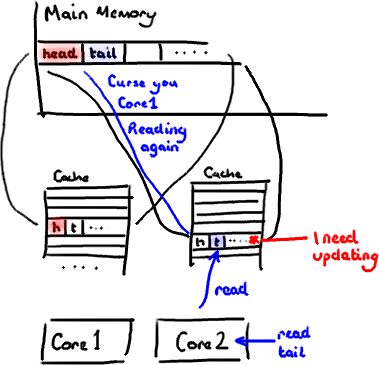 现在如果一些正在其他内核中运行的进程只是想读tail的值,整个缓存行需要从主内存重新读取。那么一个和你的消费者无关的线程读一个和head无关的值,它被缓存未命中给拖慢了。
当然如果两个独立的线程同时写两个不同的值会更糟。因为每次线程对缓存行进行写操作时,每个内核都要把另一个内核上的缓存块无效掉并重新读取里面的数据。你基本上是遇到两个线程之间的写冲突了,尽管它们写入的是不同的变量。
这叫作“伪共享”(译注:可以理解为错误的共享),因为每次你访问head你也会得到tail,而且每次你访问tail,你也会得到head。这一切都在后台发生,并且没有任何编译警告会告诉你,你正在写一个并发访问效率很低的代码。
现在如果一些正在其他内核中运行的进程只是想读tail的值,整个缓存行需要从主内存重新读取。那么一个和你的消费者无关的线程读一个和head无关的值,它被缓存未命中给拖慢了。
当然如果两个独立的线程同时写两个不同的值会更糟。因为每次线程对缓存行进行写操作时,每个内核都要把另一个内核上的缓存块无效掉并重新读取里面的数据。你基本上是遇到两个线程之间的写冲突了,尽管它们写入的是不同的变量。
这叫作“伪共享”(译注:可以理解为错误的共享),因为每次你访问head你也会得到tail,而且每次你访问tail,你也会得到head。这一切都在后台发生,并且没有任何编译警告会告诉你,你正在写一个并发访问效率很低的代码。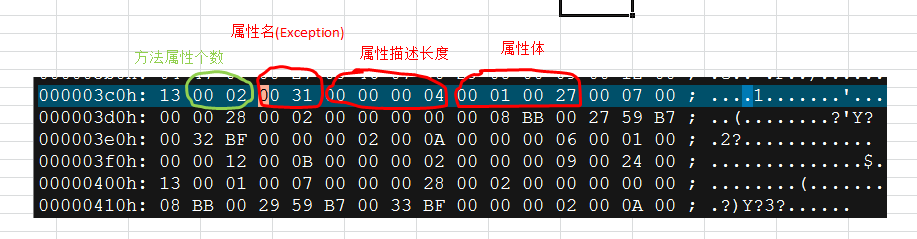
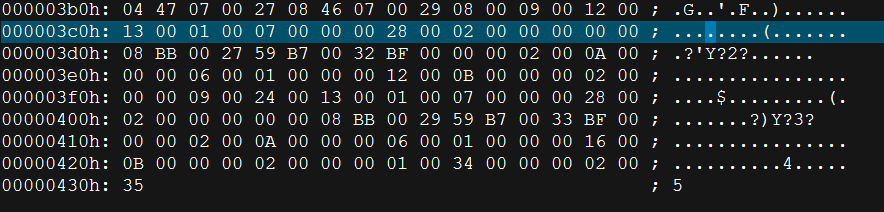
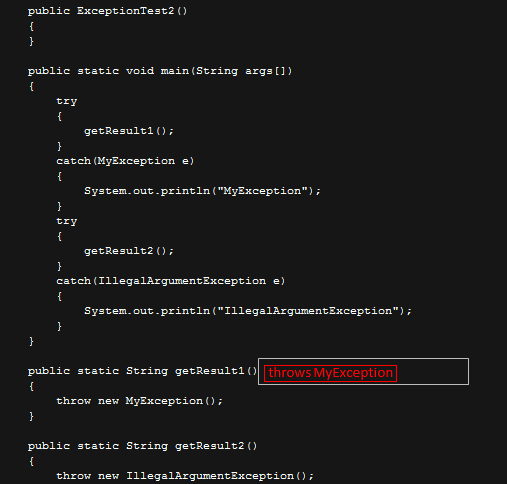 我们会发现 getResult1() 的方法的throws 信息被我们阉割掉了。
4) 运行
继续运行该class 打印结果:
我们会发现 getResult1() 的方法的throws 信息被我们阉割掉了。
4) 运行
继续运行该class 打印结果:
 5) 结论
checked 异常的throws 语句不影响class 文件的加载,且在运行时JVM没有区分这两类异常。也就是说异常机制其实在运行设计上面是没有任何差别的, 但是在使用设计上面却存在很大的差别。
5) 结论
checked 异常的throws 语句不影响class 文件的加载,且在运行时JVM没有区分这两类异常。也就是说异常机制其实在运行设计上面是没有任何差别的, 但是在使用设计上面却存在很大的差别。