一、 Exception
1. Exception定义
在有充足理由将某情况视为该方法的典型功能(typical functioning )部分时,避免使用异常。 因此,意外情况就是指方法的“正常功能”(normal functioning)之外的情况。
2. Exception分类
Checked Exception: Java.lang.Exception的子类,方法签名上需要显示的声明throws,编译器迫使调用者处理这类异常或者声明throws继续往上抛。主要是对付那些可以恢复过来的场景。
Unchecked Exception: RuntimeException的子类,方法签名不需要声明throws,编译器也不会强制调用者处理该类异常。主要用于那些无法恢复的场景。
当要决定是采用checked exception还是Unchecked exception的时候,你要问自己一个问题,”如果这种异常一旦抛出,客户端会做怎样的补救?” 如果客户端可以通过其他的方法恢复异常,那么这种异常就是checked exception; 如果客户端对出现的这种异常无能为力,那么这种异常就是Unchecked exception;从使用上讲,当异常出现的时候要做一些试图恢复它的动作而不要仅仅的打印它的信息。
3. 异常的优缺点
优点:
1). 分离错误代码和正常代码,代码更简洁。
2). 保护数据的正确性和完整性,程序更严谨及更健壮。
3). 便于调试和排错,软件更好维护。
缺点: 1). 过度或者错误使用异常会导致消耗过多的资源。 2). 有些被定义为Checked Exception的,在某些情况下并不被视为异常情况。
4. 异常处理原则:
第1条: 只针对不正常的情况才使用异常 1) 异常应该只用于异常的情况下,不该用于正常的控制流 2) 设计良好的API不应该强迫它的客户端为了正常的控制流而使用异常,可以提供状态测试(hashNext())或者可识别的返回值(return null)。
第2条: 对于可恢复的条件使用被检查的异常,对于程序错误使用运行时异常 java有三种可抛出的结构(throwable),受检的异常(checked exception)、运行时异常(run-time exception)和错误(error)。
第3条: 避免不必要的使用被检查的异常 如果正确地使用API并不能阻止这种异常条件的产生,并且一旦产生异常,使用API的程序员可以立即采取有用的动作,这种负担就被认为是正当的。除非这两个条件都成立,否则更适合于使用未受检的异常 第4条: 尽量使用标准的异常 第5条: 抛出的异常要适合于相应的抽象 1) 更高层的实现应该捕获低层的异常,同时抛出可以按照高层抽象进行解释的异常,即异常转译(Exception translation) 2) 异常链,低层的异常对于调试导致高层异常的问题有帮助的时候使用 3) 尽管异常转译与不加选择第从底层传递异常的做法相比有所改进,但是它也不能被滥用。如果可能,处理来自低层异常的最好做法是,在调用低层方法之前确保它们会成功执行,从而避免它们抛出异常。如在给低层传递参数之前,检查高层参数有效性,从而避免低层抛出异常 4) 如果无法避免低层异常,次选是,让更高层来悄悄绕开这些异常,从而将高层方法的调用者与低层的问题隔离开来。如使用java.util.logging将异常记录下来。
第6条: 每个方法抛出的 异常都要有文档 第7条: 在细节消息中包含失败 — 捕获消息 第8条: 努力使失败保持原子性,一般而言,失败的方法调用应该使对象保持在被调用之前的状态。具有这种熟悉的方法被成为具有失败原子性(failure atomic)。 1) 最简单的办法莫过于设计一个不可变的对象,如果对象不可变,失败原子性就是显然的了 2) 对于在可变对象上执行操作的方法,获得原子性最常见的办法是,在执行操作之前检查参数的有效性。 3) 做恢复代码,回滚 4) 在对象的临时拷贝上进行操作,完成之后在用临时拷贝中的结构代替对象的内容。 5) 一般而言,作为方法规范的一部分,产生任何异常都应该让对象保持在该方法调用之前的状态。如果违反这条规则,API文档就应该清楚地指明对象将会处于什么样的状态。
第9条: 不要忽略异常 1) 当api的设计者声明一个方法将抛出某个异常的时候,他们等于正在试图说明某些事情,因此不要忽略它。 2) 空的catch使异常达不到应有的目的,至少,catch块也应该保护一条说明,解释为什么可以忽略这个异常
5. Exception实例
5.1 Exception顺序
1 2 3 4 5 6 7 | |
IOException 只会catch住非FileNotFoundException以外的exception, 交换2个位置,是会编译出错的,会提示FileNotFoundException已经被catch住了。
5.2 Exception Wrapper
Exception Wrapper, 聚合这些exception, 在调用栈的顶部,封装下exception, 让上次不要知道底层这么多细节。
如果在catch或者finally的时候,抛出一个exception, 那么这个exception hide住了本来catch住的exception.
不好的实例:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
正确的写法:
1 2 3 4 5 6 7 8 9 10 11 12 | |
我们必须保证的是,最后一个exception必须throw 所有exceptions情况,其实这还不是最复杂的情况。在jdbc transations里面,情况更为复杂。
5.3 UndeclaredThrowableException
JDK的java doc是这么解释UndeclaredThrowableException的: http://download.oracle.com/technetwork/java/javase/6/docs/zh/api/java/lang/reflect/UndeclaredThrowableException.html 英文版的: http://pic.dhe.ibm.com/infocenter/adiehelp/v5r1m1/index.jsp?topic=%2Fcom.sun.api.doc%2Fjava%2Flang%2Freflect%2FUndeclaredThrowableException.html
明白了什么是UndeclaredThrowableException后,那我就查我的代码中时什么原因导致了这个exception: 这是因为通过反射调用抛出的异常被代理类包装为UndeclaredThrowableException 这个异常总共途径了一下几个系统: RPC client(源头)—–>我的应用——>Web容器(容器层) 那么我们来分析下,分别在那一层处理这个异常比较合适。 1、 源头RPC client层:我认为,判断一处代码是应该处理异常还是将异常抛出,取决于其是否获取了异常信息后,能如何应对?如果其能针对捕捉到的异常做出符合业务逻辑需要的处理,那么就不应该将异常继续抛出,反之,则抛出异常。比如上面的TimeOutException,不同应用的业务逻辑有不同的处理办法,而RPC Client端并不知道这个具体的情况,所以RPC Client不需要处理这类异常,将其继续抛出即可。越接近异常的源头,处理异常最方便(此处的方便,指的是,在接近于源头的底层框架处理异常,那么对调用这些框架的应用代码来说,就不需要关注异常处理了,这就方便了 2、 应用层:那么是不是需要在应用层做处理呢?这里需要具体情况具体分析。拿我这个应用来说,这是一个web应用,就算我这个应用对runtimeException不做处理,web容器也会对这个异常进行处理,并不会造成程序的崩溃。但是如果应用层不是web项目,或者应用不是依托在某个容器内,那如果应用层不对这个异常进行处理的话,就没人处理这个异常了,就会直接抛出一个RuntimeException,导致程序挂掉。因此我认为,如果我们在应用中调用RPC等之类的服务,要注意一下几点: 此处的调用抛了UndeclaredThrowableException,需要额外的处理不? 如果需要,就要在此处捕捉到这个异常; 如果不需要,那么就要想想,我们的应用把这个异常抛出去,接下来会不会有地方来处理这个异常,如果有,则可以继续抛出? 如果我们的应用已经是异常处理链中的最后一环,那么还是要把这个异常捕捉住。 如果有Web容器之类的罩着,我们可以把这个异常继续传递下去。 如果在应用中要处理异常,应该考虑的全面细致。是否需要降级?该流程是否是必须流程,如果是必须流程是否还会涉及到业务回滚,如果是非必须流程如何在产生异常时不影响当前业务。是否需要容灾? 3、 Web容器:上面说了,如果是Web项目,容器会处理应用抛出的RuntimeException,就像上面图展示的 Webx3容器(jboss)的默认Error页面。 另外, 对于RPC之类等涉及网络的服务调用,需要养成一个多思考一点的异常处理的编程习惯。
5.4 异常的性能问题
1) 问题存在 是否使用异常来控制业务流程,是个比较争议的话题。支持的人认为,使用业务异常来控制业务流程,代码逻辑清晰,反对的人认为异常消耗太多资源,对系统的性能有影响。那我们做个测试,看看异常是否会影响性能。 首先定义一个普通的业务异常,代码如下:
1 2 3 4 5 6 7 8 9 | |
然后测试对比,生成业务异常对象和生成普通对象的耗时分别是多少,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
最后的执行结果如下:
1 2 | |
2) 原因分析 可见生成普通HashMap对象和普通业务异常对象的耗时不在一个数量级,那我们看看生成业务异常对象,做了哪些事情,查看Exception的父类Throwable的构造函数,发现构造普通业务异常对象的时候,会调用synchronized声明的方法fillInStackTrace,代码如下:
1 2 3 4 | |
性能的主要开销就在这个方法,作用是填充线程运行堆栈信息,其实定义业务异常是为了用于控制业务逻辑,为可检查异常,其堆栈信息没有多大用处,生成业务异常的时候,没有必要填充堆栈信息。 3) 解决方法 对BusinessException做了改进,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
对方法fillInStackTrace进行了重写,此时我们再测试一次,结果如下:
1 2 | |
此时就不会因为业务异常而影响系统性能。
5.5 运行时异常和可检查异常的差别
这个差别主要表现在编程时和运行时,编程时差别大家都比较清楚, checked异常总是需要显式处理, 而unchecked异常可以选择性处理,那么在运行时呢,这两个异常JVM处理上面是否存在很大的差异? 1) Java文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
2) class阉割
将编译好的class 文件使用二进制方式打开,找到如下位置:
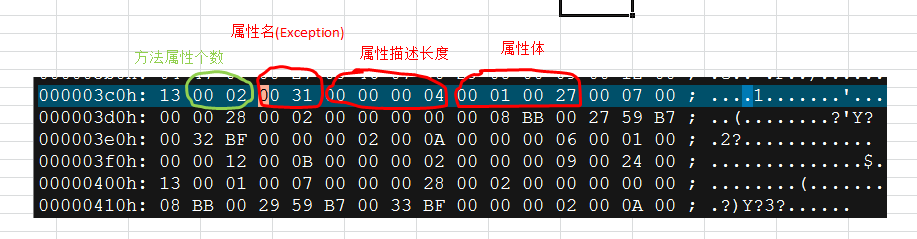
我们 将绿色部分修改成0001 , 将红色部分删除:
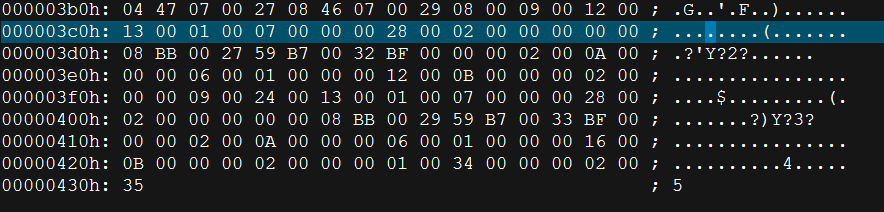
3) 反编译
将该class 反编译成java :
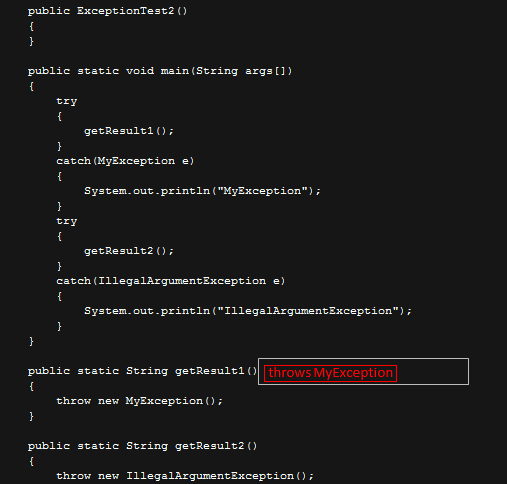 我们会发现 getResult1() 的方法的throws 信息被我们阉割掉了。
4) 运行
继续运行该class 打印结果:
我们会发现 getResult1() 的方法的throws 信息被我们阉割掉了。
4) 运行
继续运行该class 打印结果:
 5) 结论
checked 异常的throws 语句不影响class 文件的加载,且在运行时JVM没有区分这两类异常。也就是说异常机制其实在运行设计上面是没有任何差别的, 但是在使用设计上面却存在很大的差别。
5) 结论
checked 异常的throws 语句不影响class 文件的加载,且在运行时JVM没有区分这两类异常。也就是说异常机制其实在运行设计上面是没有任何差别的, 但是在使用设计上面却存在很大的差别。
6. Java-7中新增exception特性
6.1 特性一 Java 7 Try-with-resourcce
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
在JSR 334, Project Coin
1 2 3 4 5 6 7 8 9 10 11 | |
这个FileInputStream会在try block完成时,被自动关掉,因为FileInputStream实现了Java.lang.AutoCloseable接口,所有class实现了这个接口,都可以用在try-with-resources结果里面。
当多个Resouces申明了以后,
try( FileInputStream input = new FileInputStream("file.txt");
BufferedInputStream bufferedInput = new BufferedInputStream(input)
) {
input, bufferedInput都会自动关闭,但是他们关闭的顺序正好和他们申明顺序相反。
6.2 特性二 Java7 之前我们catch住多个Exception
1 2 3 4 5 6 7 8 9 | |
Java 7之后 我们可以用
1 2 3 4 5 6 7 | |
如果用一个比较大的父类的Exception, 这会造成上层用户,很难知道到底发生了什么。 7. 异常实现原理(JVM) JVM对异常的处理主要是基于异常表(Exception Table),每个包含了try的方法在编译后除字节码外,都会产生一个附加的数据结构—异常表,异常表结构如下:
{
{PC:BEGIN, PC:END, PC:HANDLER, EXCEPTION-TYPE}
}
PC:BEGIN-PC:END 代表异常发生的PC值的范围
EXCEPTION-TYPE 代表异常捕获的类型
PC:HANDLER 代表异常处理的指针
当JVM的方法产生异常后,按照以下步骤执行异常处理: 1. JVM会在当前Frame的Exception Table里面逐条查找PC范围和异常类型匹配的记录。 并将PC跳转到对应的异常处理的位置上。 注意:类型符合不是完全匹配,而是符合向上原则,即父类的catch可以捕获子类的对象,即 e instance of CLASS。 2. 如果当前Frame不存在Exception Table, 或者在Exception Table里找不到匹配的记录,则当前Frame出栈,把当前Frame设置成上一个Frame,获得新的当前pc和当前异常表。 3. 继续执行1,直到JAVA STACK到达栈底还不能匹配,则异常未处理,抛出到JRE。
个人理解:JVM是基于所谓的栈帧的(stack frame)的,一个函数调用链就是一个个栈帧组成,当在一个栈里用athrow抛出异常时,JVM会搜索当前函数的异常处理表(参考下面的Class文件分析),如果有找到对应的异常处理的handler,则由这个handler来处理。如果没有,则清理当前栈,再回到上一层栈帧中处理。如果一层层栈帧回退,最 athrow指令: 在JVM里实现异常的指令是athrow,指令的参考在这里:http://docs.oracle.com/javase/specs/jvms/se7/html/jvms-6.html#jvms-6.5.athrow 终都没有找到Exception Handler,则线程终止。
8. 带finally的异常处理
如果异常处理带有finally块,字节码的处理同上面的异常处理流程一致, JVM并不需要为此机制作出改动。编译器通过内联函数和扩展异常表来实现的这个过程。 可以这么理解finally,有异常发生的时候,可以理解为一个可以捕获方法内任何异常(包含try块中的异常和catch块中的异常)并自动重新抛出的catch段。 在没有异常,或者异常被捕获的过程,以字节码内联的方式将finally段内容自动添加到对应的段后,然后自动执行。 注意:如果finally段内如果有return关键字的话,异常已经被捕获,在再次抛出之前,return导致了Frame的出栈,从而导致后面的(athrow)没有执行,JVM的异常状态神奇的消失了。所以在代码实现上面,一定要避免这种有违异常约定的写法(eclipse也会提醒)。