概述
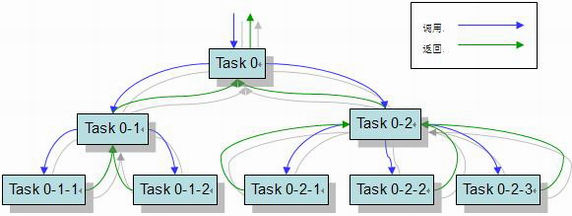
fork/join框架是ExecutorService接口的一种具体实现,目的是为了帮助更好地利用多处理器带来的好处。它是为那些能够被递归地拆解成子任务的工作类型量身设计的。其目的在于能够使用所有可用的运算能力来提升你的应用的性能。 Fork/Join 模式有自己的适用范围。如果一个应用能被分解成多个子任务,并且组合多个子任务的结果就能够获得最终的答案,那么这个应用就适合用 Fork/Join 模式来解决。 Fork就是把一个大任务切分为若干子任务并行的执行,Join就是合并这些子任务的执行结果,最后得到这个大任务的结果。比如计算1+2+……+10000,可以分割成10个子任务,每个子任务分别对1000个数进行求和,最终汇总这10个子任务的结果。Fork/Join的运行流程图如下:
fork/join框架的核心是ForkJoinPool类,它是对AbstractExecutorService类的扩展。ForkJoinPool实现了工作偷取算法,并可以执行ForkJoinTask任务。
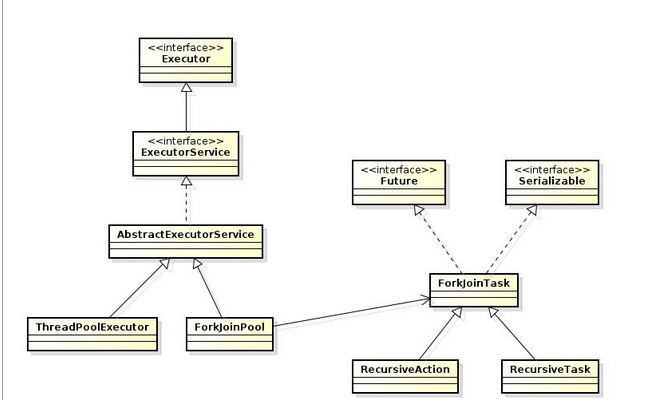
ExecutorService扩展了Executor并添加了一些生命周期管理的方法。一个Executor的生命周期有三种状态,运行 ,关闭 ,终止。Executor创建时处于运行状态。当调用ExecutorService.shutdown()后,处于关闭状态,isShutdown()方法返回true。这时,不应该再想Executor中添加任务,所有已添加的任务执行完毕后,Executor处于终止状态,isTerminated()返回true 并发问题可以很容易地通过Callable线程的Executor接口来解决,通过为每个任务实例化一 个Callable实例,并在ExecutorService类中汇总计算结果来得出最终结果可以实现这一目的。 使 用ExecutorService和Callable的主要问题是,Callable实例在本质上是阻塞的。一旦一个Callable实例开始执行,其他所有Callable都会被阻塞。由于队列后面的Callable实例在前一实例未执行完成的时候不会被执行,因此许多资源无法得到利用。
Fork/Join框架被引入解决并行问题,而Executor解决的是并发问题。 ForkJoinPool和ThreadPoolExecutor共同继承与AbstractExecutorService;ForkjoinPool使用到了RecursiveAction和RecursiveTask。他们两个中RecursiveAction应用于执行的任务不需要返回结果的场景,而RecursiveTask应用于需要返回执行结果的场景。这点类似于ThreadPoolExecutor使用Runnable和Callable的参数来分别表示不需要返回值和需要返回值的线程执行对象。 ForkJoinPool由ForkJoinTask数组 和ForkJoinWorkerThread数组组成,ForkJoinTask数组负责存放程序提交给ForkJoinPool的任务,而ForkJoinWorkerThread数组负责执行这些任务。 其中ForkJoinPool有三个用来提交或开始任务的方法: submit:异步的执行Task,并且在任务结束后,可以使用getRawResult()方法获取返回值;在获取返回值之前,可能需要使用如 isQuiescent () 方法判断当前任务的执行结果。 execute:同submit类似,但是不带返回值 invoke:同submit类似,但是是同步的。 其余重要方法: shutdown():执行此方法之后,ForkJoinPool 不再接受新的任务,但是已经提交的任务可以继续执行。如果希望立刻停止所有的任务,可以尝试 shutdownNow() 方法 awaitTermination():阻塞当前线程直到 ForkJoinPool 中所有的任务都执行结束
而ForkJoinTask也有两个用来执行的方法: fork:类似于上面的submi invoke:类似于上面的invoke方法
ForkJoinTask的fork方法实现原理。当我们调用ForkJoinTask的fork方法时,程序会调用ForkJoinWorkerThread的pushTask方法异步的执行这个任务,然后立即返回结果。代码如下:
1 2 3 4 5 | |
pushTask方法把当前任务存放在ForkJoinTask数组queue里。然后再调用ForkJoinPool的signalWork()方法唤醒或创建一个工作线程来执行任务。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 | |
ForkJoinTask的join方法实现原理。Join方法的主要作用是阻塞当前线程并等待获取结果。让我们一起看看ForkJoinTask的join方法的实现,代码如下:
1 2 3 4 5 6 | |
首先,它调用了doJoin()方法,通过doJoin()方法得到当前任务的状态来判断返回什么结果,任务状态有四种:已完成(NORMAL),被取消(CANCELLED),信号(SIGNAL)和出现异常(EXCEPTIONAL)。 q 如果任务状态是已完成,则直接返回任务结果。 q 如果任务状态是被取消,则直接抛出CancellationException。 q 如果任务状态是抛出异常,则直接抛出对应的异常。
在doJoin()方法里,首先通过查看任务的状态,看任务是否已经执行完了,如果执行完了,则直接返回任务状态,如果没有执行完,则从任务数组里取出任务并执行。如果任务顺利执行完成了,则设置任务状态为NORMAL,如果出现异常,则纪录异常,并将任务状态设置为EXCEPTIONAL。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
关于工作窃取
fork/join框架会将任务分发给线程池中的工作线程。fork/join框架的独特之处在与它使用工作窃取(work-stealing)算法。完成自己的工作而处于空闲的工作线程能够从其他仍然处于忙碌(busy)状态的工作线程处窃取等待执行的任务。
每个工作线程都有自己的工作队列,这是使用双端队列(或者叫做 deque)来实现的。当一个任务划分一个新线程时,它将自己推到 deque 的头部。
当线程的任务队列为空,它将尝试从另一个线程的 deque 的尾部 窃取另一个任务。
与标准队列相比,deque 具有两方面的优势:减少争用和窃取。
因为只有工作线程会访问自身的 deque 的头部,deque 头部永远不会发生争用;
因为只有当一个线程空闲时才会访问 deque 的尾部,所以也很少存在线程的 deque 尾部的争用。
跟传统的基于线程池的方法相比,减少争用会大大降低同步成本。此外,这种方法暗含的后进先出(last-in-first-out,LIFO)任务排队机制意味着最大的任务排在队列的尾部,当另一个线程需要窃取任务时,它将得到一个能够分解成多个小任务的任务,从而避免了在未来窃取任务。因此,工作窃取实现了合理的负载平衡,无需进行协调并且将同步成本降到了最小。

实例一:斐波那契数列 公式定义: f(n) = f(n-1) + f(n-2); n-2 >0; f(1)=1; f(2)=2; 使用Fork/Join框架实现多任务的并发执行计算,以n=25为例,数据结构分析:
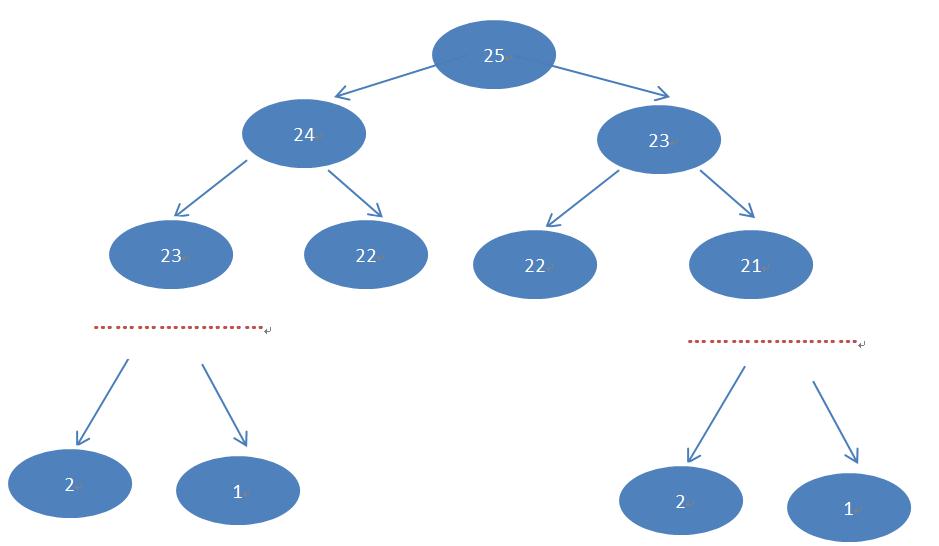
详见代码FibonnaciTask.7z; 讲解点: a.fork和join的先进后出关系;b.递归调用和join的先后对性能的影响
实例二:合并排序实例(对比单线程、ExecutorService实现、Fork/Join实现的性能)
实例流程说明:

Partition方法算法(子任务拆分算法)说明:
步骤一:生成随机数填充的数组(取正负100以内的值) 23 -24 65 53 90 87 …… 66 步骤二:以数据最后一个值,做为分拣标准,小于的向左,大于的向右: 23 -24 65 53 66 87 …… 90 步骤三:以标准值做为分界点,任务一拆为二 Task1: 23 -24 65 53 66 Task2: 87 …… 90 步骤四:重复步骤一,直到子任务小于阀值
详见代码TestForkJoinSimple.7z; 讲解点:a. ExecutorService的代码实现;b.好的性能对比例子; c.不好的性能对比例子